
We introduce Directional Stimulus Prompting, a novel framework for guiding black-box large language models (LLMs) toward specific desired outputs. Instead of directly adjusting LLMs, our method employs a small tunable policy model (e.g., T5) to generate an auxiliary directional stimulus prompt for each input instance. These directional stimulus prompts act as nuanced, instance-specific hints and clues to guide LLMs in generating desired outcomes, such as including specific keywords in the generated summary. Our approach sidesteps the challenges of direct LLM tuning by optimizing the policy model to explore directional stimulus prompts that align LLMs with desired behaviors. The policy model can be optimized through 1) supervised fine-tuning using labeled data and 2) reinforcement learning from offline or online rewards based on the LLM's output. We assess our method across summarization, dialogue response generation, and chain-of-thought reasoning tasks. Our experiments demonstrate that the framework consistently improves LLMs' (e.g., ChatGPT, Codex, InstructGPT) performance on these supervised tasks using minimal labeled data. Notably, using just 80 dialogues on the MultiWOZ dataset, our approach enhances ChatGPT's performance by an impressive 41.4%, matching or surpassing some fully supervised start-of-the-art models. Additionally, the instance-specific chain-of-thought prompt generated by our approach improves InstructGPT's reasoning accuracy compared to human-crafted or automatically generated prompts, showcasing its effectiveness as an automatic prompt engineering/optimization approach.
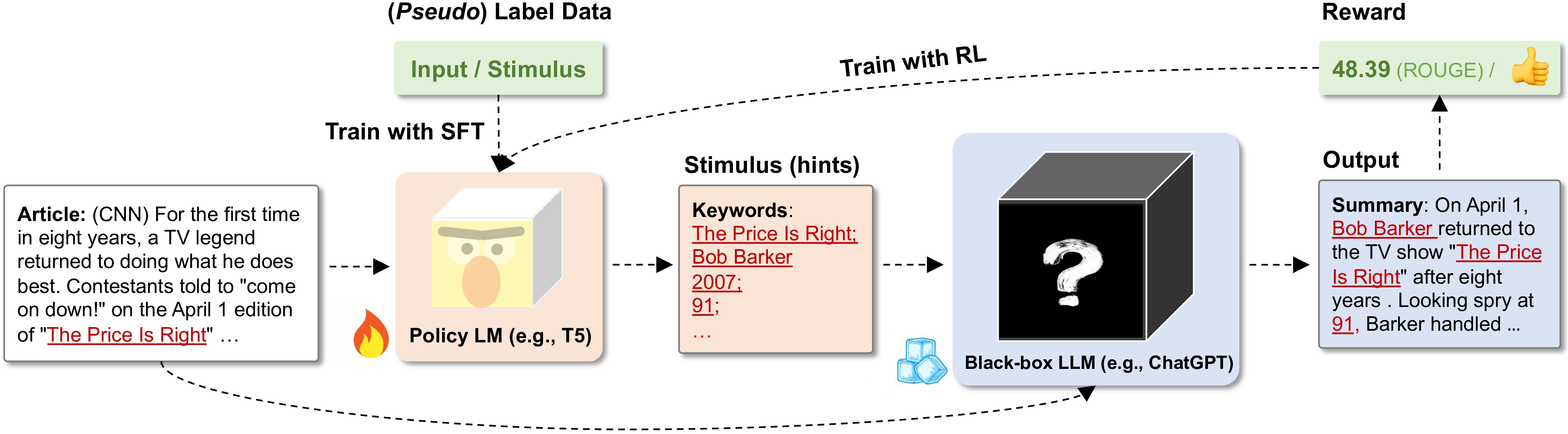
We utilize a relatively small and tunable LM (e.g., T5), as the policy model to generate the directional
stimulus prompt for each input query. This approach enables us to sidestep the direct optimization
of black-box LLMs by optimizing the small tunable policy model instead. We train the policy
model through supervised fine-tuning (SFT) using a few collected labeled data. After supervised
fine-tuning, we further optimize the policy model to explore better directional stimulus prompts
with reinforcement learning (RL). During RL training, we aim to maximize the reward defined as
downstream performance measures or any other measures of the LLM's output conditioned on the
stimulus generated by the policy model.
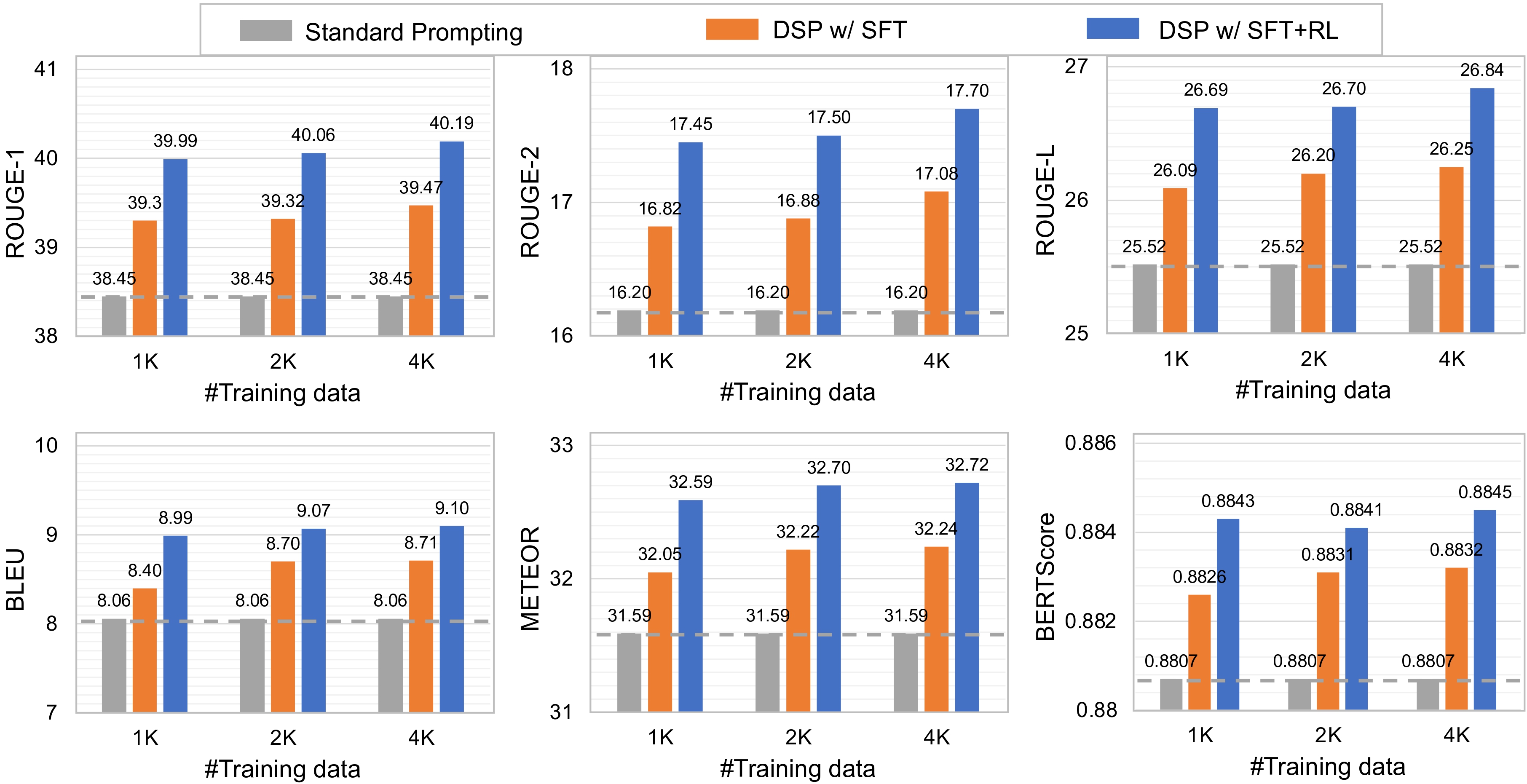
All the evaluation scores improve with our proposed DSP compared with standard prompting.
Supervised fine-tuning (SFT) improves the benchmark performance, while additional RL results in further performance improvement, as it effectively encourages the policy model to explore better directional stimulus that maximizes the reward.
Despite using a small collection of only 1,000 to 4,000 samples to keep API usage costs low, our DSP approach still consistently enhances ChatGPT's ROUGE, BLEU, and Meteor scores, even though ChatGPT has already achieved considerable performance.
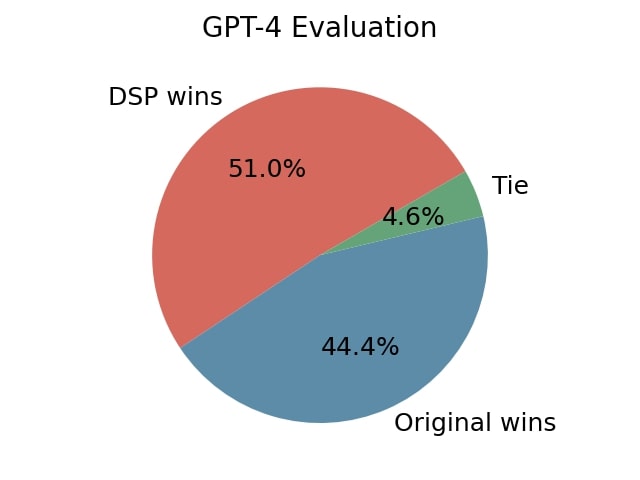
To gain a better understanding of generated summaries guided by keywords, we employed GPT-4 to evaluate
them using the prompt given below. The results are shown in Figure 4.
We found that GPT-4 can produce reasonable and detailed explanations of their assessment.
From our test set of 500 samples: DSP-generated summaries were favored 255 times (51.0%), summaries generated with original standard prompting were favored 222
times (44.4%), while a tie was observed in 23 cases (4.6%).
You are provided with an article and a corresponding reference summary. Additionally, there will be two alternative summaries labeled as 'A' and 'B'.
Your task is to identify which of the two summaries (A or B) is more similar to the reference summary. This similarity should be evaluated based on the presence and accuracy of key points from the reference summary in each alternative summary.
Please detail your reasoning in an explanation. After your explanation, classify the task outcome as: select 'A wins' if Summary A aligns more closely with the reference summary, 'B wins' if Summary B aligns more closely, or 'Tie' if both summaries align equally well with the reference summary.
Current LLM-based chatbots such as ChatGPT and Claude are typically targeted at open-domain conversations while struggling with task-oriented (goal-oriented) dialogues where they need to assist users in completing specific goals or tasks, such as making reservations or ordering food.
Unlike open-domain conversations, task-oriented dialogues often require the chatbot to follow task-specific business logic and respond based on reliable information from API calls or database queries.
To address this limitation, we train the policy model to generate dialogue acts, which are used to guide the LLMs in generate reliable system responses that assist users in completing tasks and goals.
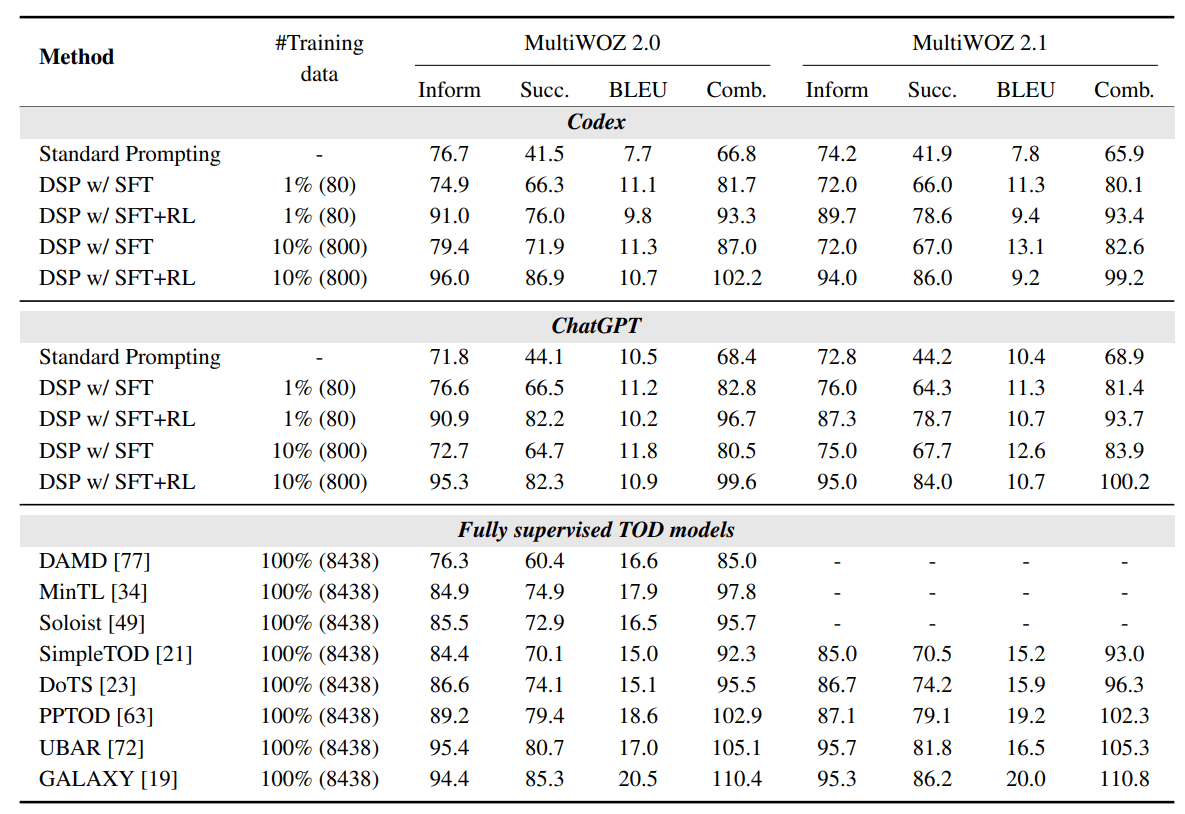
From Table 1 we can see that our approach DSP significantly improves the success and inform rates of Codex and ChatGPT, even with only 80 dialogues,
surpassing several fully trained TOD models, particularly in terms of Success and Inform rates.
While current methods primarily utilize generalized task-specific prompts, LLMs exhibit sensitivity to these prompts.
DSP could serves as an automatic prompt engineering/optimization approach.
Notably, our approach is able to generate instance-specific prompts, instead of the task-specific prompts as in previous work.
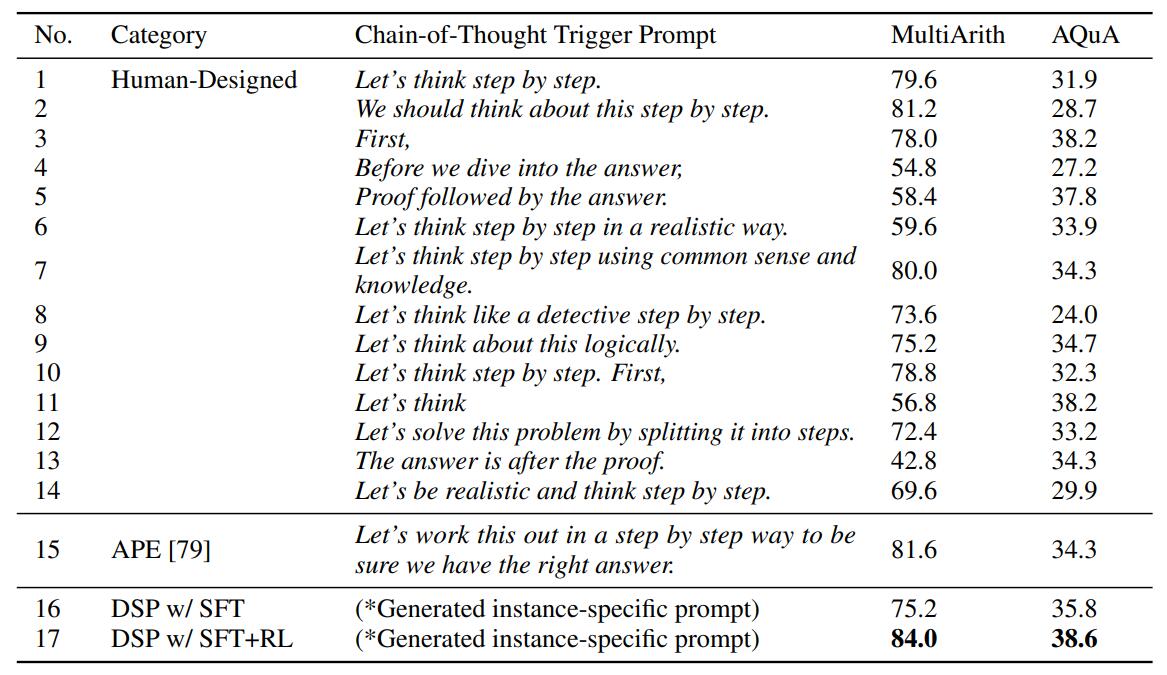
As can be seen in Table 2, InstructGPT’s performance
varies significantly when using different task-specific prompts. Compared to the 14 task-specific
human-designed prompts, DSP enhances the performance with instance-specific prompts. It also
outperforms the prompt discovered by the APE approach.
After fine-tuning with RL, the policy model is encouraged to explore better
instance-specific trigger prompts (some are shown in Table 3), further improving performance.

In this paper, we introduce Directional Stimulus Prompting (DSP), a new prompting framework to provide black-box LLMs with fine-grained and instance-specific guidance toward the desired outputs. We use a tunable policy model to generate the directional stimulus to provide such guidance and convert the optimization of black-box LLMs to that of the policy model. Experimental results demonstrate the effectiveness of our approach in controlling and guiding black-box LLMs via automatic prompt engineering and optimization. Furthermore, the generated stimulus provides valuable insights and interpretations of LLMs' behaviors. In this work, we use heuristically selected or annotated pseudo-stimulus data for supervised fine-tuning of the policy model. For future work, we hope to explore the possibility of using a “machine language” between the policy model and the LLMs that might not be intuitively preferred by humans but can better convey guidance information, as well as other forms of directional stimulus beyond text.
@misc{li2023guiding,
title={Guiding Large Language Models via Directional Stimulus Prompting},
author={Zekun Li and Baolin Peng and Pengcheng He and Michel Galley and Jianfeng Gao and Xifeng Yan},
year={2023},
eprint={2302.11520},
archivePrefix={arXiv},
primaryClass={cs.CL}
}